
Token:AI 的「積木」與你的荷包
Token:AI 的「積木」與你的荷包
在上一篇文章中,我們介紹了語言模型的核心機制其實就是一場高超的「文字接龍」遊戲 。AI 透過閱讀海量訓練資料,學會了預測下一個最可能出現的單位 。
然而,這個被預測的「單位」究竟是什麼?為什麼經常頭頭是道的 AI,竟然連簡單的加減法都會算錯,甚至數不清楚單字裡有幾個字母?要理解這個現象,得從語言模型最基本的組成單位開始: Token。
積木不等於文字
許多初次使用大語言模型的人都有過這種困惑:它能寫出條理分明的程式碼,卻在一些小學生等級的問題上跌大跤。這並不是因為它「笨」,我們可以把 Token 想像成語言模型用來搭建世界的「積木」,它看世界的方式是由 token 堆疊而成的,這導致了幾個常見的「認知錯覺」:
- 數學幻覺:
對人類來說,「1000」是一個數值;但對 AI 來說,這只是積木的排列。在某些模型的眼中,「1000」可能被拆解成「 10 」和「 00 」兩塊積木。當 AI 進行接龍時,它不是在做運算,而是在預測「接在 10 和 00 後面的積木應該是什麼」。這就是為什麼它有時候會一本正經地算出錯誤答案。 - 字母盲視(The Lollipop Problem):
如果你問 AI:「Lollipop 這個字裡面有幾個 l ?」,它經常會答錯。為什麼?因為在 AI 的眼裡,Lollipop 往往是一整塊積木(或是 Lol + lipop 兩塊)。它無法像人類一樣直接「看見」組成這塊積木的個別字母 l-o-l-l-i-p-o-p,除非它運用外部的工具,先把這塊積木打碎(拼寫出來)。 - 字數失控:
你也許遇過這種情況:要求 AI「寫一篇 500 字的文章」,結果它寫了 800 字或只有 300 字。這是因為使用者計算的是「字(Word)」,但 AI 計算的是「積木(Token)」。不同語言、不同詞彙的「積木化」比例不同,AI 很難精準計算 token 換算成人類文字確切有多少字元。
Token 也是計價單位
理解 Token 的第二個層次,其實很現實且充滿銅臭味:Token 是 AI 時代的計價單位與效能指標。
如果使用者打算使用 API 開發應用,會發現語言模型服務商有一堆關於 Token 的術語:
- 計價單位: AI 服務通常不是按「次」收費,而是按「Token 使用量」計價。這賦予了「字字珠璣」全新的意義。使用者輸入的內容(Prompt)和 AI 回答的每一個字,都在消耗預算。這也是為什麼在中文語境下,有時候使用 AI 比較貴。因為中文的一個字可能包含多個含義,兩三個詞連在一起,可能還組合出不同言外之意,因此往往需要更多 token 來組成 。
- 如果需要將語言模型部署到自己採購的硬體當中,使用者還必須認識到評估效能的單位:
- Tk/s(Tokens per second): 這是衡量 AI「思考速度」的關鍵指標。數值越高,代表 AI 生成文字像機關槍一樣快;數值越低,就像老舊打字機一樣慢吞吞。
- Time to First Token: 當使用者按下 Enter 後,AI 吐出第一個 token 需要等待的時間。這代表了 AI 的反應速度,也是影響使用者體驗最直接的指標。
- 人們在線上使用 chatGPT 、 Gemini 或 Grok 等雲端 AI 服務,之所以能快速回覆超級長的內容,就是因為廠商用超高規格的硬體,增強語言模型的反應能力。
Tokenizer 幫你看見「接縫」
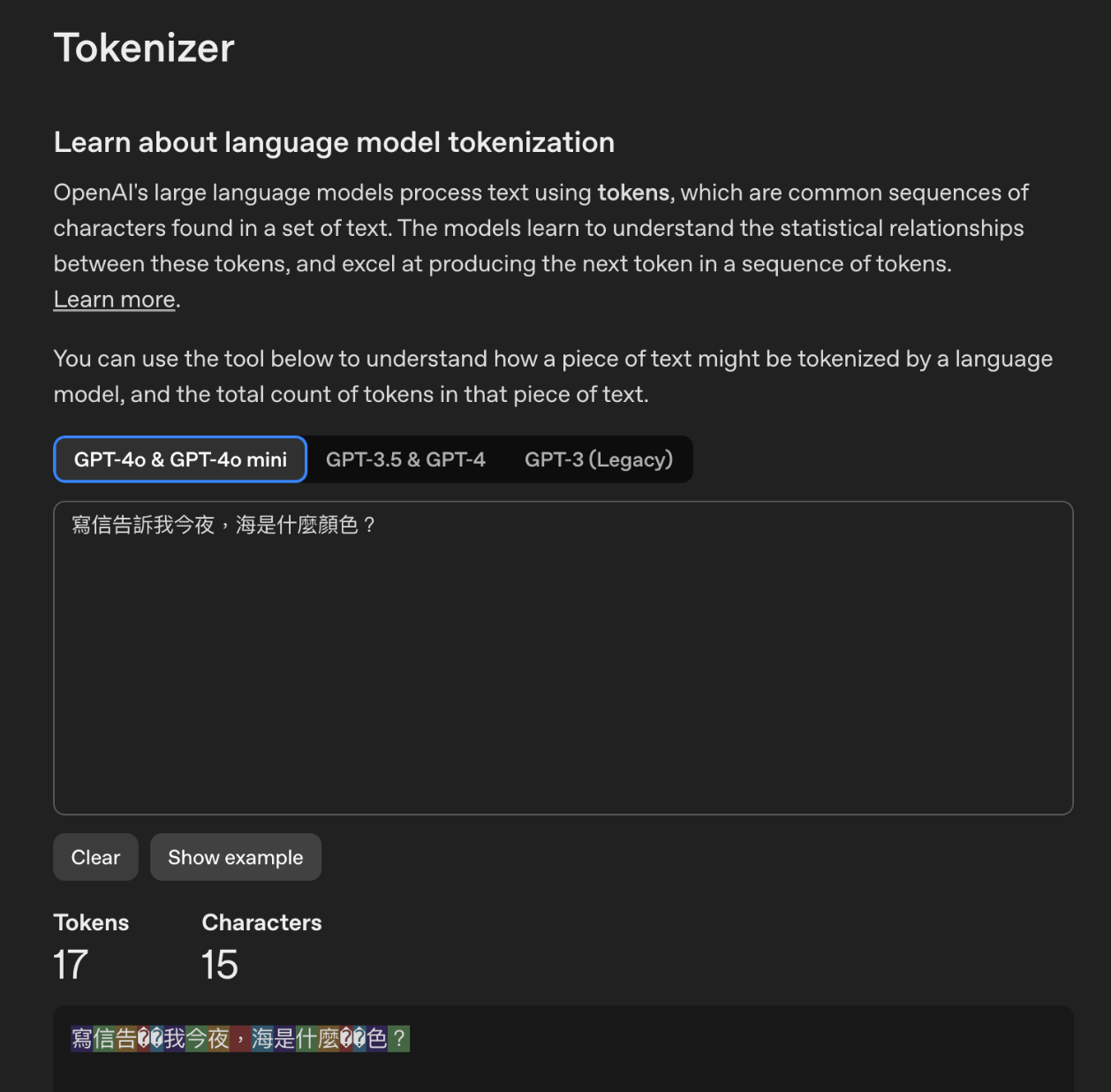
為了讓開發者理解 AI 到底「看」到了什麼, AI 公司也會提供了 Tokenizer 視覺化工具。透過這些工具,使用者可以看到一句話是如何被拆解的。當 Prompt 效果不佳,去檢查 Token 的切分方式,也許能找到病灶。可能是一個特殊的符號被切成了十幾個無意義的碎積木,浪費了寶貴的視窗空間與金錢。
例如 openAI 有提供一個線上計算 token 數量的服務 https://platform.openai.com/tokenizer ,在上面多算幾次,會發現語言模型跟人類理解自然語言的方式,還是有不少落差。
記憶的極限:Context Window 與逐漸模糊的注意力
回到原理,為什麼 Token 如此重要,與 Transformer 架構的「注意力機制」有關 。
- 上下文視窗(Context Window): 這是模型一次能放在工作檯上的最大積木數量。你可以把它想像成 AI 的短期記憶容量。
- 注意力疲勞: 雖然現在的模型號稱可以讀完一整本書,但你可能會發現,當對話越來越長,積木堆得越來越高,AI 開始變得健忘,或者邏輯變差。這是因為注意力機制必須在數萬個積木中尋找關聯,資訊量越大,雜訊就越多。
- 實用建議: 所以,如果你覺得對話到後來, AI 變笨了,或者開始鬼打牆,最好的解法通常是「開啟一個新的對話視窗」。這就像把桌上的積木全掃掉,讓 AI 清空工作記憶,重新專注在當前的新任務上。
回顧 AI 發展史,也是一部 Context Window 的擴張史。從 GPT-1 時代只能記住幾百個積木 ,到現在可以處理百萬級別 token 的 Gemini 或 Claude,記憶體與電力成本也隨之暴漲 。
為了不讓昂貴的積木塞爆視窗,人類也有採取一些聰明的作法,試圖改善模型的表現:
- RAG(檢索增強生成): 既然記不住所有事,不如給 AI 一本「參考書」。當你問問題時,系統先去書裡翻找相關段落,只把最關鍵的資訊餵給 AI。這樣既省錢,又能減少 AI 胡說八道的「幻覺」。
- CAG(快取增強生成): 如果你總是問同一份文件的問題,CAG 技術可以把這些積木「暫存」起來,不用每次都重新排練一次,大幅降低延遲與成本。
結語
Token 是 AI 思考的「積木」,也是使用者付費的「單位」。簡單來說,理解 token 、使用者就能設計適合的 Prompt。
為了讓經費預算與 AI 的算力都發揮最大效益,可以參考以下與 AI 協作的策略:
- 別急著開始對話,先動腦:
- 不要像擠牙膏一樣,一句一句試探 AI。這樣既浪費 Token,也容易讓 AI 在越來越長的對話中迷失方向。試著在一開始就寫下結構完整、指令明確的長篇 Prompt,一次把背景、要求、範例講清楚。
- 採取「會前會」:
- 如果不知道該怎麼寫出精準的 Prompt,可以先開一個視窗,請 AI 幫你擬定:「我要做某某任務,請幫我寫一個精緻的 Prompt。」然後在討論完之後,拿 AI 幫忙草擬的精準 Prompt ,複製它,開啟一個全新的對話視窗貼上。這樣能確保 AI 在最乾淨、無雜訊的狀態下,用更少的積木消耗,交出更高品質的成果。
- 別當成即時通訊在跟 AI 聊天,善用「格式」:
- 很多人習慣像傳 LINE 一樣,想到一句打一句,連標點符號都省了。這對 AI 來說,就像是一堆沒有分類的散亂積木,增加了預測下一塊積木的難度 。
- 除了標點符號之外,也可以試著使用基礎的 Markdown 語法 來整理思路,例如用 # 標示標題層級、用 – 條列重點、用 > 區隔引用資料。 因為 AI 的訓練資料包含大量程式碼與結構化文件,它對這些符號非常敏感。使用格式把「指令」、「背景」與「參考資料」區隔開來,就像是在茫茫的 Token 海洋中建立了清晰的「路標」,能幫助 AI 精準辨識你的意圖,大幅減少誤讀與胡言亂語的機率。